-
m-relay
<elongated:matrix.org> Are we fighting risc-v miners ? Or bitmain can update code and still use it ?
-
kico
sech1, wouldn't it be possible to take a look at the nounces and try and figure for how long these have been mining? x9 I mean
-
sech1
It looks like they use the same firmware, so nonce patterns didn't change
-
DataHoarder
You can measure the increase of nonce patterns over time
-
DataHoarder
-
DataHoarder
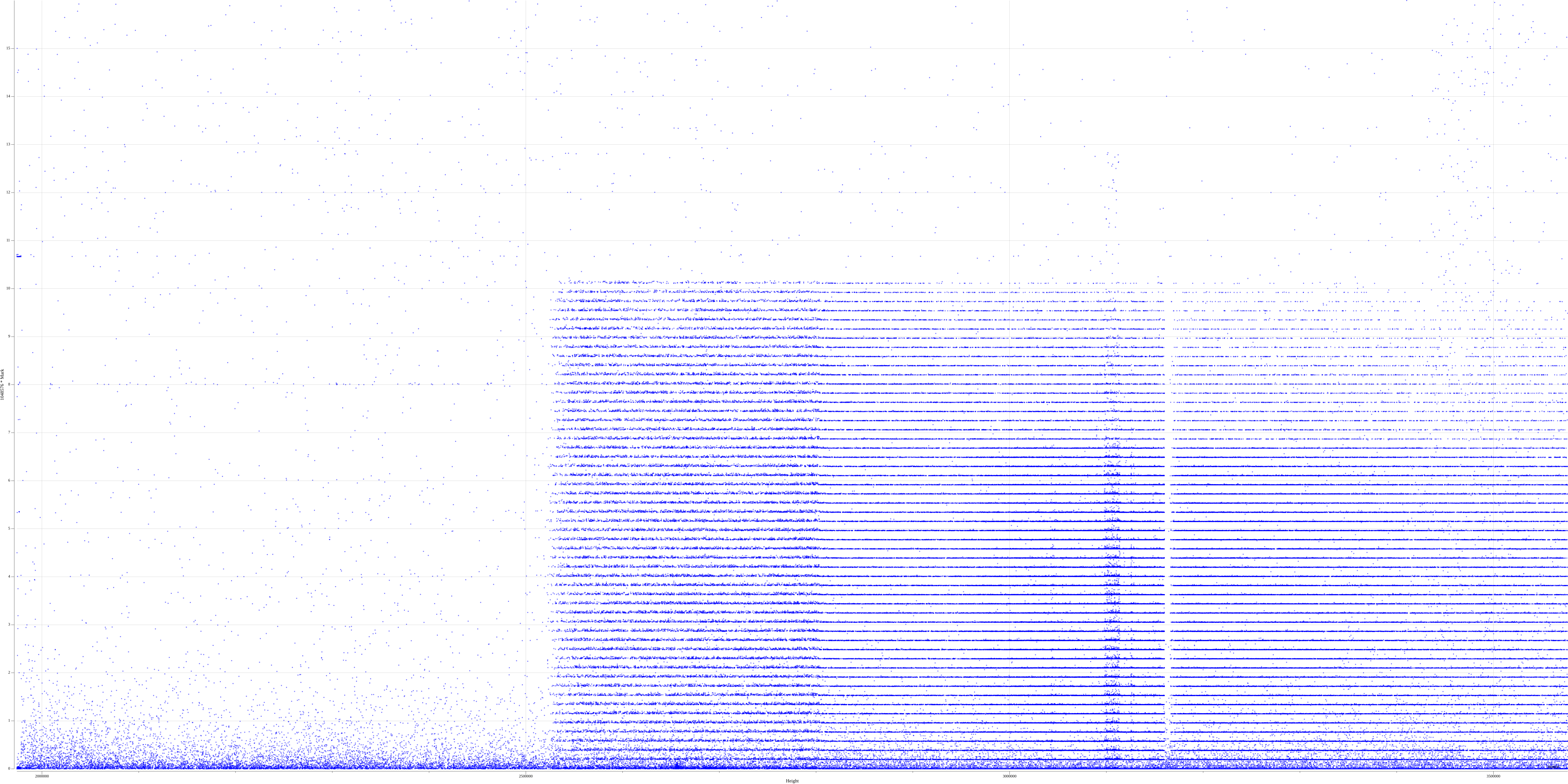
remade nonce pattern, from randomx fork or so to last block today
-
DataHoarder
-
DataHoarder
nonce % 2^28, remove groups nonce / 2^28 that are 0 or > 10 (0 has a lot of contamination, and higher ones don't appear in nonces)
-
DataHoarder
then their pattern is on the bottom 1/16th of this. That is the range of the plot
-
DataHoarder
that has their sub-patterns
-
hyc
so they've improved effciency 1.6x. About what we expected.
-
hyc
still a shame that other commodity risc-v boards aren't very good
-
sech1
the best CPU rig that I'm aware of is 7945hx 19.2kh 85w @wall
-
sech1
225 h/J
-
sech1
X9 is 400 h/J
-
sech1
not even 2x better
-
sech1
Still, we need RandomX v2
-
hyc
yeah. 1.77x better
-
sech1
I wonder how many RAM sticks they put into X9
-
sech1
must be at least 60
-
hyc
with the price of RAM going thru the roof again, Bitmain would make more money cannibalizing the existing X9s for their RAM
-
hyc
it's silly...
-
sech1
although, that 7945HX can get 20 kh/s with more power, and it runs on a single stick of DDR5 (tuned timings)
-
hyc
DDR5 now is 4x its price in September...
-
hyc
-
sech1
btw I'm done with RISC-V code for XMRig, the next step is to bring to upstream repo and then finally implement the v2 part for RISC-V. Then only the small things will be left
-
sech1
I even added hardware AES support for RISC-V
-
sech1
Without actual hardware I can test on :D
-
sech1
yeah, RAM prices are insane
-
hyc
lol. maybe bitmain has already tested it :P
-
sech1
maybe :D
-
hyc
I think right now the RAM is worth more than it could ever make from mining
-
sech1
I think that RandomX program size must be bumped a lot for v2
-
sech1
like from 256 to 320 instructions (+25%)
-
sech1
because Zen4/Zen5 wait a lot for data from RAM
-
sech1
they became much faster than Zen2
-
hyc
ah, make more use of instruction cache?
-
sech1
more use of computing capacity
-
hyc
sounds good
-
sech1
they have better IPC and better clocks than 3700X which was the king when RandomX released
-
sech1
Instruction frequencies will need to be adjusted to avoid getting FP registers into +- infinity territory
-
sech1
because that will hurt entropy
-
sech1
but yeah, Zen5 can do 320 instructions instead of 256, almost at the same hashrate (and with CFROUND fix)
-
hyc
25% better ipc huh
-
hyc
I wonder how that affects arm64, Apple M2
-
DataHoarder
L2 caches per thread have also grown quite a bit, while L3 have stayed ... the same
-
DataHoarder
without X3D ofc
-
sech1
FSQRT instruction is the best to keep FP registers away from overflow/underflow. It basically halves the exponent
-
kico
I'm sure bitmain bought RAM for these inb4 the crazyness
-
kico
they usually "test" their HW for 1 year
-
kico
this miner has probably been in the making for a few years now
-
sech1
It's probably been in the making ever since they started selling (=dumping) X5
-
sech1
Oh hi tevador
-
kico
exactly :P
-
sech1
Which means they already have X11 or something in the works
-
kico
hehehe
-
kico
x5, x9 ... x13?
-
tevador
new "ASIC"?
-
sech1
tevador I plan to work on RandomX v2 in January and prepare the complete pull request when it's done
-
tevador
cool
-
sech1
btw I added RISC-V vector JIT + dataset init + vector AES + hardware AES code to XMRig
-
sech1
All that code will be added to upstream too
-
DataHoarder
if they are mining with that it's not with the same nonce pattern afaik
-
sech1
And for v2, I want to increase program size, like a lot (+25%)
-
sech1
256 -> 320
-
sech1
and increase FSQRT frequency to keep FP registers in range
-
DataHoarder
the density of the nonce pattern has decreased over time, though I now need to calculate the actual hashrate of the bands (weighted by difficulty)
-
sech1
btw at this point, they can just take stock XMRig (dev branch) and use it on X9 :D
-
sech1
so nonce pattern will be the regular one
-
DataHoarder
now, yes. but not say couple of years ago since they released other one
-
sech1
yes
-
tevador
are there any existing risc-v chips with hardware AES?
-
sech1
my Orange Pi RV2 has vector extensions but not AES
-
sech1
When I asked, I got this answer: "Bunch of SiFive cores has crypto extensions. X280, X390, P470, P670, P870."
-
tevador
there are scalar and vector crypto extensions
-
sech1
QEMU supports everything so I was able to verify my code, but it can still break on the real hardware
-
sech1
I implemented scalar crypto extensions
-
sech1
zknd/zkne
-
sech1
I haven't heard about vector AES on RISC-V, and I read all the specs
-
tevador
-
sech1
That one I didn't read
-
sech1
-
sech1
so it's a newer extension
-
sech1
oh well, another version to implement?
-
sech1
luckily RandomX AES is not a lot of code
-
tevador
According to the latest RVA profile, vector crypto should be preferred:
github.com/riscv/riscv-profiles/releases/tag/rva23-rvb23-ratified
-
tevador
"The scalar crypto extensions Zkn and Zks that were options in RVA22 are not options in RVA23. The goal is for both hardware and software vendors to move to use vector crypto, as vectors are now mandatory and vector crypto is substantially faster than scalar crypto."
-
sech1
oh, they even have vror instruction for vector registers
-
sech1
I guess I'll added detection of zvkb and zvkned extensions too, before bringing it upstream
-
sech1
*add
-
sech1
yeah, I'm not a fan of having two hardware AES implementations for RISC-V
-
sech1
I already have vectorized soft AES, so vectorized hard AES only makes more sense
-
sech1
"vectors are now mandatory" that's good
-
tevador
Btw, I'd also suggest to bump the CBRANCH jump frequency to at least 1/32 (currently 1/256).
-
tevador
HashX was broken by GPUs because of insufficient branching.
-
sech1
HashX is not RandomX, it doesn't do 2048 loop iterations
-
sech1
25/256*2048 = 200 taken branches per program on average
-
sech1
and it's just one program at a time which can be compiled for GPUs, if I read the description right
-
sech1
Then yes, only branching can save it from GPUs.
-
tevador
I forgot why we chose 1/256. Perhaps the misprediction overhead was measurable at 1/128, but it could be retested with current hardware.
-
sech1
because of misprediction stalls in the pipeline
-
sech1
these branches are essentially random and can't be predicted
-
tevador
I doesn't need to hurt with SMT because the other thread can run.
-
tevador
It*
-
DataHoarder
> To take advantage of speculative designs, the random programs should contain branches. However, if branch prediction fails, the speculatively executed instructions are thrown away, which results in a certain amount of wasted energy with each misprediction. Therefore we should aim to minimize the number of mispredictions.
-
sech1
oh yes, and this too
-
DataHoarder
> Unfortunately, we haven't found a way how to utilize branch prediction in RandomX. Because RandomX is a consensus protocol, all the rules must be set out in advance, which includes the rules for branches.
-
DataHoarder
branch prediction - isn't that specific for the CPU? nowadays the predictors for speculation can remember values of registers at certain branches, and if they follow a pattern
-
sech1
so 200 taken branches per program = 200xN wasted instructions executed and rolled back
-
tevador
Still doesn't explain why 1/256 was selected rather than 1/128.
-
sech1
N = pipeline depth
-
sech1
the smallest possible value was chosen
-
sech1
because we already have a lot of CBRANCH instructions in the code
-
sech1
they needed to be frequent to limit instruction reordering optimizations for simple in-order CPUs
-
sech1
The question is, 200 taken branches per program is too little or enough?
-
sech1
btw increasing program size will also increase the number of branches
-
tevador
Yes, it might be enough just to increase the program size.
-
sech1
and frequent branches also limit VLIW CPUs
-
DataHoarder
and number of CFROUND on avg :)
-
DataHoarder
but also decrease frequency they switch
-
sech1
CFROUND was nerfed in another way in v2
-
DataHoarder
indeed
-
DataHoarder
CBRANCH 1/25 is the second most frequent op after FMUL_R 1/32
-
DataHoarder
err, 25/256, 32/256
-
sech1
Increasing program size to 320 will require increasing FSQRT_R from 6/256 to 7 or even 8, to keep FP registers in range
-
sech1
so some other frequencies will need to be reduced
-
sech1
IXOR_R can probably be a donor.
-
DataHoarder
15/256
-
sech1
it doesn't do much in terms of energy required
-
sech1
unlike FSQRT_R
-
DataHoarder
XOR is just carryless ADD in GF(2) :)
-
sech1
making RandomX burn more energy and in places where AMD/Intel CPUs are best optimized (FPU) is the goal
-
sech1
sounds counter-intuitive :D
-
DataHoarder
specifically float64
-
sech1
because in the end it will make AMD/Intel CPUs more efficient, relative to X9
-
DataHoarder
where the ai/accelerator stuff is f32 or less :P
-
sech1
Internally in the CPU, sqrt is implemented as a table lookup + a few multiplications, so it burns more energy than even FMUL
-
sech1
*a few FMAs
-
tevador
Zen5 misprediction penalty is ~15 cycles, so ~24000 cycles per hash are wasted currently. It might be OK.
-
sech1
much more is wasted when it's waiting for dataset read
-
sech1
it's still keeping most of the CPU powered on in these moments
-
sech1
which is why 256 -> 320 increase is crucial
-
sech1
if it's powered on, it only makes sense to make it keep executing instructions until dataset read is guaranteed ready on most systems
-
tevador
Btw, reducing IXOR_R would have a side effect of reducing the mixing of integer registers.
-
sech1
yes, but letting FP registers almost always overflow/underflow will hurt entropy even more. Need to do real tests with v2 and 320 program size to make sure their exponents cover the full range, but rarely reach overflow/underflow
-
tevador
It might be better to transfer from FMUL_R, which is the main cause of needing a higher FSQRT_R frequency.
-
sech1
then it will be obviouse which sqrt frequency is the best
-
sech1
we don't need a lot of square roots, because they halve the exponent each time
-
sech1
so it's logarithmic dependency
-
sech1
FMUL_R can be a donor too
-
tevador
Probably RANDOMX_FREQ_FMUL_R 32 -> 30 and RANDOMX_FREQ_FSQRT_R 6 -> 8
-
sech1
too high frequency will reduce exponent range, so we will need tests
-
sech1
maybe 6 will still be enough, because the amount of square roots will also increase by 25%
-
tevador
-
tevador
However, I can't find the source code for the test
-
sech1
not a problem, I will just modify the interpreter to collect the statistics
-
sech1
hyc MO discord has a sensible idea: if X9 has to pack this much RAM inside, maybe it's soldered RAM this time? It takes much less space, and they don't need to put a 16 GB memory stick per CPU. 2x2 GB memory chips will be enough
-
sech1
So double the dataset in v2? :D
-
DataHoarder
^ I tried allocating the dataset via WASM on browser and it just worked btw
-
sech1
4 GB dataset / 512 MB light mode is okay now, it's not 2019 anymore
-
DataHoarder
they lowered from 4 GiB to 2 GiB afaik
-
sech1
btw 4 GB dataset was considered for the original RandomX
-
DataHoarder
yeah, I remember reading that up
-
DataHoarder
or maybe they brought that back up again
v8.dev/blog/4gb-wasm-memory
-
m-relay
<syntheticbird:monero.social> sech1. Exactly we're in 2025. RAM is more expensive than ever
-
m-relay
<syntheticbird:monero.social> WE NEED 10KB DATASET NOW
-
m-relay
<syntheticbird:monero.social> I CANNOT SURVIVE WITHOUT IT
-
m-relay
<syntheticbird:monero.social> HEEEEEELLLLLLLPPPPPPPPPP
-
sech1
Even single DDR4 stick is 8 GB, so it won't change anything in terms of what miners need to buy
-
sech1
Raspberry Pi's will lose, but using them for mining is a bad idea anyway. For anything else, they can use light mode
-
tevador
Remember that the current monerod code allocates two caches, so it already uses 512 MB with light mode.
-
hyc
Any increases in footprint will bump up hardware requirements
-
m-relay
<elongated:matrix.org> High time we increase hw requirements
-
hyc
it may make a lot of current nodes & miners nonviable
-
m-relay
<elongated:matrix.org> Nodes ? Yes, botnets will be affected
-
hyc
yes, nodes too. dataset ram will compete with blockchain cache
-
sech1
light mode will require 1 GB then, so 2 GB minimum for running monerod
-
m-relay
<syntheticbird:monero.social> Are we sure we wanna piss off one of our significant portion of the hashrate while operations like qubit showcased the fragility of your current miner landscape
-
m-relay
<syntheticbird:monero.social> our current*
-
m-relay
<syntheticbird:monero.social> Yes, i believe botnets are a significant portion of the hashrate
-
m-relay
<syntheticbird:monero.social> you may now proceed to shame me
-
sech1
I'm not sure about dataset increase just to brick the X9. Because it's not guaranteed - maybe they have 8 GB per CPU, so it won't stop them
{kind=link}
{kind=link}