-
crypto_grampy[m]
<gingeropolous> "im betting a second p2pool is..." <- We should come up with a name for og-p2pool soon
-
nioc
sechistheone
-
crypto_grampy[m]
I like that. If someone creates a new pool, would it just use a different port? How do you know which p2pool you're on if there are multiple?
-
gingeropolous
yeah i think its just different port
-
crypto_grampy[m]
I don't understand this stuff at all, but would it make any sense to add a unique id? So everyone who wants to start their own p2pool uses the same port, but you connect with peers that run with the same unique id... I.e. pool name which could be sechistheone
-
crypto_grampy[m]
If you want to switch pools, you set the pool name and connect to an IP of a known peer in that pool?
-
crypto_grampy[m]
s/set/change/
-
DataHoarder
There is already an unique id created based on consensus parameters crypto_grampy[m]
-
DataHoarder
the issue with more p2pool is 51% attacks that just grab rewards gingeropolous (they can’t do anything Monero wise, just change what shares get paid)
-
minereni_d
Hey everyone
-
minereni_d
I'm noticing the number of upstreams on my xmrig proxy keeps increasing, while the number of miners remains the same
-
minereni_d
[2021-11-04 09:27:28.308] proxy 150.00 kH/s, shares: 4/0 +0, upstreams: 24, miners: 24 (max 24) +0/-0
-
minereni_d
[2021-11-04 09:28:28.568] proxy 100.00 kH/s, shares: 4/0 +0, upstreams: 27, miners: 24 (max 24) +3/-3
-
minereni_d
Then I also notice that p2pool actually sends work items 1 for each upstream
-
minereni_d
Is it normal that I receive more upstreams than workers? are these upstreams garbage collected somehow?
-
hv-bridge
<sech1> if you run xmrig-proxy in simple mode then 1 upstream = 1 miner
-
hv-bridge
<sech1> it probably keeps an upstream for a while after miner disconnects
-
minereni_d
yes, I use it in simple mode, as I understand this is the way to run it with p2pool
-
minereni_d
I've never seen the upstream number go down eventually
-
\x
hyc sech1 everyone
-
\x
-
pauliouk
damn
-
pauliouk
not bad - expensive bit of kit I'm guessing?
-
\x
needs optimization or prolly latency too high
-
\x
pauliouk: 5400 is pretty low end for ddr5
-
\x
7000 at the topend with an xOC 2 dimmer board
-
\x
they say 6400 is attainable by most chips on the daily
-
hv-bridge
-
\x
-
\x
sech1
-
hv-bridge
<sech1> so ~8.9 kh/s on Monero and ~10.4 kh/s on Wownero
-
hv-bridge
<sech1> just as I expected
-
\x
sech1: okay man, done with that bench, maybe youll get more in a few days heh
-
\x
gonna bother the guy for other stuff now
-
\x
sech1: did it run properly?
-
hv-bridge
<sech1> looks like it did
-
\x
sech1: p-cores have avx512 but for now intel disabled it since windows cant handle it
-
\x
like e-cores dont have it
-
\x
so when running certain stuff it uhhhh
-
\x
illegal instruction
-
\x
intel will likely re-enable it idk
-
hv-bridge
<sech1> avx512 is a waste
-
\x
an early asus bios enables you to toggle it and it loads an older microcode and it disables the e-cores
-
hv-bridge
<sech1> better have more smaller cores without avx512
-
\x
intel is still gonna try to enable it
-
\x
but yeah, needs software support
-
\x
just a heads up
-
\x
sech1: i cant promise a 1t run as it takes too much time and evryone is asking those guy to run meme benchmarks
-
\x
maybe domorrow ill get the guy to run 1t
-
\x
-
\x
sech1: interested on an avx512 run or is it really useless for you?
-
hv-bridge
<sech1> useless
-
hv-bridge
-
\x
kk
-
hv-bridge
<sech1> huge L3 latency
-
hv-bridge
<sech1> 1T RandomX will be bad
-
\x
how many minutes do you expect for 1M?
-
\x
1t 1M
-
\x
i just cant bother the guy to run a long benchmark for now, every fucker on the room is asking for 3dmark stuff with weird settings
-
hv-bridge
<sech1> probably ~900 h/s, so 17-19 minutes
-
\x
lmao
-
\x
so rocketlake still 1t king
-
hv-bridge
<sech1> 1t can wait
-
\x
kk
-
\x
yeah good thing this guy woke up on time now
-
\x
and i got the first benchmark after nda lift
-
hv-bridge
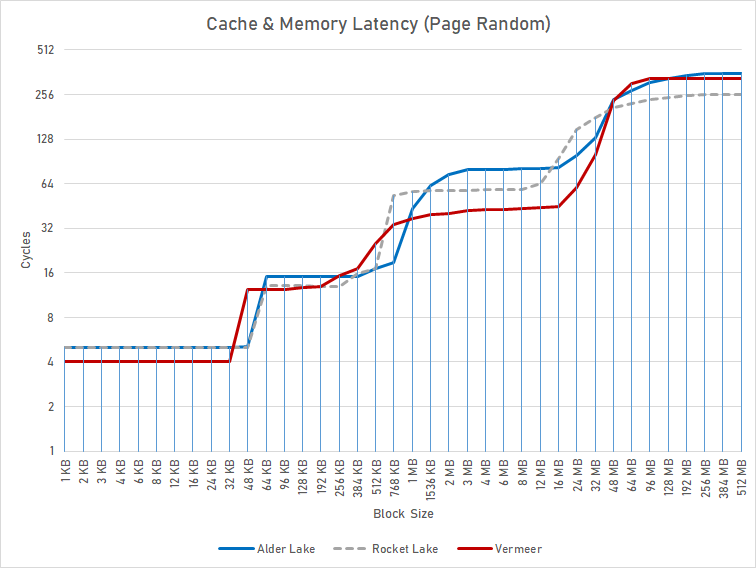
<sech1> 40 cycles on Zen3 vs 65 cycles on Alder Lake
-
\x
sech1: im still impressed on the performance though
-
\x
not bad for the first try of big little on x86
-
\x
im sure there will be growing pains but yeah, not bad
-
\x
intel is back man
-
\x
intel is back
-
nioc
So 12900 = 3700
-
\x
for mining ye
-
\x
intel still a cachelet
-
hyc
sech1: are you able to reproduce the core_tests crash on arm64/jit ?
-
hv-bridge
<sech1> I only have RPi4 and it overheats under prolonged load and then reboots or hangs
-
pauliouk
sech1, want me to send you a heat sink kit and 3v fan? :) keeps mine running
-
hv-bridge
<sech1> I have a heat sink there. It only works fine if I open the window and put my RPi4 under cold air from the street 🙂
-
pauliouk
fresh air is always a plus I guess :)
-
\x
sech1: you seem spot on, guy said its doing 900 h.s on 1t
-
\x
based sech1
-
\x
anyway, we will finish the bench
-
\x
-
hyc
ok I'm running under gdb again, will grab disasssembly when it dies
-
hyc
folks please use #monero-mining or something for general p2pool usage stuff
-
hyc
this channel should be development focused
-
hyc
-
nioc
there is also #p2pool-log for p2pool chatter
-
hyc
let me know if you want more context before/after there
-
hyc
paste.debian.net/1218231 same thing, with hex bytes
-
sech1
so it was a call to randomx_calc_dataset_item_aarch64 that landed in unmapped memory
-
sech1
it looks like linker bug to me
-
sech1
or no, it's not a linker bug. randomx_calc_dataset_item_aarch64 is copied to allocated memory to construct super scalar hash code
-
sech1
hyc you need to print out CodeSize and CalcDatasetItemSize to see how much it allocates. It uses pointer differences between function pointer, maybe it's actually some linker magic that breaks things
-
hyc
randomx::CodeSize = 13464
-
hyc
randomx::CalcDatasetItemSize = 66308
-
hyc
the memory region is 81920 bytes, should have been large enough for all of that
-
hyc
the target address is far below the beginning of the region
-
hyc
+++++++++++++
-
hyc
sech1 what values do you get in your build?
-
sech1
these values look correct. I need to remember how it's actually JITted
-
sech1
hyc that "bl 0xffffe1f70438" is definitely wrong, it should jump to 0x0000ffffe1f95... because JIT doesn't overwrite jump destination there. It only overwrite previous two "add" instructions
-
sech1
maybe linker error
-
sech1
can you try compiling and running xmrig there? It has the same code there
-
hyc
afaik this only fails in core_tests
-
hyc
this box is currently running both monerod and p2pool, so this code is already live on the box
-
hyc
I have previously run xmrig on here without any problems either
-
hyc
maybe I can figure out how to set a watchpoint on that branch instr and trap when it gets overwritten
-
hyc
or I wonder if there's just garbage in there left over from a previous testcase
-
wfaressuissia
What's the minimal reproduction you have ?
-
wfaressuissia
`tests/core_tests/core_tests --generate_and_play_test_data --filter gen_block_big_major_version` does it fail with this filter ?
-
wfaressuissia
did you try to reduce it to single rx_slow_hash call ?
-
sech1
if it's a linker error, just calling rx_slow_hash from anywhere within that binary should cras
-
sech1
*crash
-
sech1
actually, it's better to search for the machine code "ea 03 00 91" (mov x10, sp) and check what's before it in working binary and crashing binary
-
sech1
this instruction should be unique enough to find RandomX code
-
hyc
running now with the filter
-
hyc
SEGv'd again
-
hyc
different stacktrace tho
-
hyc
#0 0x0000ffffe1d6f438 in ?? ()
-
hyc
only 1 stack frame, nothing else
-
wfaressuissia
can you set preliminary breakpoint on rx_slow_hash, it must be the first call
-
hyc
ok trying again with breakpoint
-
hyc
hit breakpoint, now what?
-
wfaressuissia
`finish`
-
hyc
segv
-
wfaressuissia
set breakpoint on randomx_calculate_hash
-
wfaressuissia
and step manually
-
wfaressuissia
there will be few steps before actual jit
-
wfaressuissia
and then likely few instructions within jit and segv
-
hyc
ok running
-
wfaressuissia
cache init stage is not interesting, it can be even commented probably
-
sech1
the actual JIT code execution starts at "compiler.getProgramFunc()(reg, mem, scratchpad, RANDOMX_PROGRAM_ITERATIONS);" in vm_compiled.cpp
-
hyc
yeah I'm stepping thru asm code now
-
hyc
this could take a while, one instr at a time
-
hyc
ok, segv
-
hyc
gahh. the process disappeared, can't inspect memory*////
-
hyc
trying again. cat was on kbd
-
wfaressuissia
`one instr at a time` you could do `99999 si` and `1 si` and then bisect actual number of instructions before seg
-
wfaressuissia
but `si` is useful only within jit, c++ can be stepped with simple `step`
-
hyc
ok I have it
-
hyc
-
sech1
well, the jump offset is the same in both cases
-
hyc
yes. the execution was completely linear from 91000 to 91b38
-
hyc
then it branched to 94430
-
sech1
I mean the bl instruction that jump to unmapped memory
-
hyc
yeah it's the same bytes as before
-
sech1
it's probably linker bug
-
sech1
I blame binutils again
-
hyc
hmmm
-
sech1
IIRC we had problem with it on ARM before
-
selsta
does ARM on Mac use JIT?
-
hyc
yes
-
sech1
-
hyc
so this is gnu ld 2.34
-
hyc
ubuntu 20.04.2 lts
-
wfaressuissia
-
sech1
yes
-
sech1
-
sech1
but jump instruction is not touched there
-
hyc
hmmmm
-
hyc
that symbol is not present in the .o file
-
hyc
oh there it is
-
hyc
-
hyc
maybe reordering chunks in the source file would avoid the problem
-
wfaressuissia
disassemble this randomx_program_aarch64_light_dataset_offset, what is the destination of relative jump there ? is it randomx_calc_dataset_item_aarch64 ?
-
wfaressuissia
you can disassemble executable with objdump / gdb / anything else
-
hyc
sure
-
hyc
it is <randomx_calc_dataset_item_aarch64@plt>
-
hyc
it's treating it as an external global, not a local reference
-
hyc
that would explain the problem, it needs to jump thru the plt to get fixed up to the correct address
-
wfaressuissia
and jit is doing stupid memcpy of asm with assumption that it's PIE
-
hyc
and that's not happening here
-
wfaressuissia
PIC (position independent code)
-
hyc
yes
-
hyc
dunno how to force the asm to emit a relative branch here
-
sech1
it should be PIC
-
wfaressuissia
`as -fPIC ...` ?
-
sech1
it's a local jump within the same .S file
-
hyc
well, it has assembled as a global reference, not a local
-
sech1
probably because randomx_calc_dataset_item_aarch64 is used in jit_compiler_a64.cpp
-
sech1
but it should've optimized it to relative jump during linking
-
hyc
still, it would be better to just emit it as local and leave it alone. I wonder if reordering so it's not a forward reference would make any difference
-
hyc
or just give randomx_calc_dataset_item_aarch64 2 labels, one local
-
sech1
yeah, but how you can be sure it's the only place like this
-
sech1
maybe it's first of many
-
hyc
hmmm. ok will objdump the .o
-
sech1
actually they're all declared as globel (see first lines of jit_compiler_a64_static.S)
-
hyc
they appear to be relocatable references in the .o file instead of relative
-
wfaressuissia
-
wfaressuissia
"
paste.debian.net/hidden/9831a12f" build with clang and shared libs failed on some jump within jit too
-
wfaressuissia
and it was x86_64
-
hyc
I'm going to insert a bunch of local labels in here and see if it makes a difference
-
wfaressuissia
-
hyc
yes, inserting and using local labels works, the global references are gone
-
hyc
test succeeds
-
wfaressuissia
can you patch x86_64 jit, i'll repeat the above test with clang
-
wfaressuissia
* ... write patch for x86_64 jit and share it ...
-
hyc
ok, gimme a couple minutes
-
hyc
-
hyc
I'll add the x86 patch to this branch
-
wfaressuissia
works
-
wfaressuissia
-
hyc
I'm fixing up one more reference
-
hyc
line 151
-
hyc
rx_dataset_init
-
hyc
that seems to be all
-
hyc
I presume the .asm file should get the same change
-
wfaressuissia
maybe
-
hyc
I guess randomx_dataset_init was safe because it's within the same function
-
hyc
but whatever, I changed it already, will leave it in
-
hyc
ok, branch updated. we need someone to build on windows to test the .asm file
-
wfaressuissia
not me
-
hyc
yeah, I don't have recent msvc here either
-
selsta
is running randomx-tests enough?
-
hyc
probably
-
selsta
(don't know if that uses jit)
-
selsta
I can run it on Windows CI
-
hyc
cool. but is it actually building with msvc or with gnu toolchain?
-
wfaressuissia
the last unanswered question, why did it fail only within core_tests ?
-
hyc
or mebbe I should just leave the .asm source untouched, since nobody has reported a crash in windows
-
hyc
probably because it's dynamic linking librandomx.so
-
hyc
wfaressuissia: in a static build there would be no PLT reference
-
hyc
dunno
-
wfaressuissia
can verify this hypothesis somehow quickly ? via build logs maybe
-
hyc
I didn't build tests on my release build, lemme check
-
hyc
release build def builds static librarry, debug build uses shared library
-
wfaressuissia
core_tests fails independently on build type (debug/release), right ?
-
sech1
actually I had a lot of similar problems with debug MSVC builds
-
sech1
it always replaced pointer to functions to pointers to jmp instructions that jumped to actual functions
-
hyc
ok, then the .asm patch should prob help
-
hyc
wfaressuissia: I suppose it would still fail on release build if it assembled an absolute addr reference instead of a relative one
-
wfaressuissia
why monerod works independently on build type then ?
-
hyc
link time optimization?
-
wfaressuissia
core_tests and monerod are both executables in the end, what's the difference ?
-
hyc
dunno
-
hyc
the release build definitely assembled absolute references on master
-
hyc
but monerod binary has relative references there
-
hyc
gdb monerod ; disass/r randomx_program_aarch64_light_dataset_offset
-
hyc
so monerod works because the linker did the right thing there
-
wfaressuissia
what bit to flip in order to get the same problem in monerod as in core_tests ?
-
wfaressuissia
* which bit ...
-
hyc
good question
-
hyc
my release build of core_tests doesn't crash. the code has a relative reference
-
hyc
so it's only a problem with dynamic librandomx.so
-
wfaressuissia
then all questions are answered
{kind=link}
{kind=link}